
Overview
Association Rule Mining (ARM) is a technique to find interesting associations and relationships among large sets of data items which can be said that the goal is to find patterns in the data. This rule shows how frequently an item occurs in a transaction. This method can only be used with transaction data.
The most common application of association rule mining is in market basket analysis, where it is used to identify purchasing patterns in retail transactions. A shopper puts items from a store into a basket. Once the customer has a few products in their basket, it is possible to suggest to them related items that are on the store’s shelves. For instance, a typical association rule might be: If a customer buys product A and product B, then there is a high probability they will also buy product C. The concept is to bring a set of products together that have some kind of interdependency in terms of their use. Putting them together may stimulate or remind customers of the need for the related product, which will increase sales. To tackle this problem, the association rule called the Apriori Algorithm is considered.
Apriori Algorithm
The Apriori algorithm significantly reduces the search space for discovering frequent itemsets and association rules by exploiting the apriori property. This results in a more efficient and practical approach to finding meaningful patterns in large datasets.
It follows three measures to find associations. Below is an example of how these measures are calculated.

Items bought in different transactions
From the figure above, it can be seen that there are 10 transactions.
- Support
The support of an item is how frequently the item occurs in all transactions. It is the fraction of the total number of transactions wherein the itemset is shown.
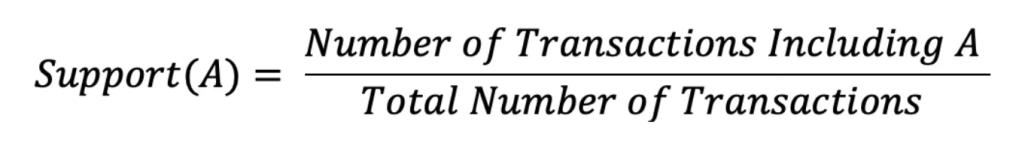
For example:
Support (Perfume) = 4/10 = 0.4 = 40%
This means that 40% of the transactions include perfume.
2. Confidence
Confidence is the likelihood of occurrence of items together in a dataset.
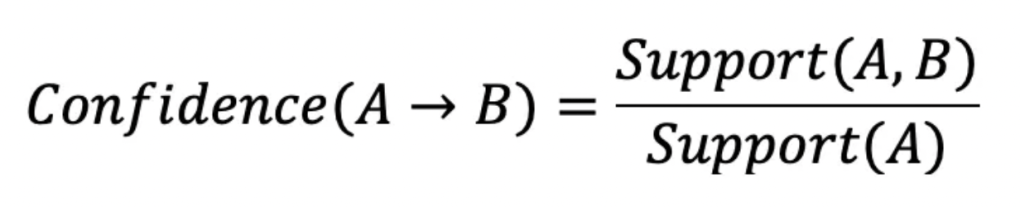
For example:
Confidence (Perfume -> Soap) = Support (Perfume U Soap) / Support (Perfume)
= 0.3/0.4 = 75%
Means 75% of the time when a customer buys perfume with soap.
3. Lift
Lift is a ratio of confidence and support.
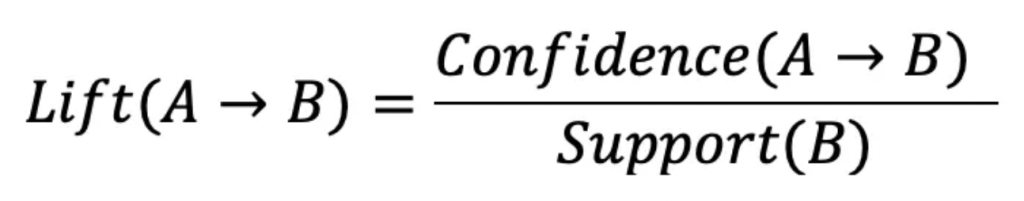
If Lift = 1, means the sale of items A and B are independent and there is no association. The occurrence of the antecedent (left-hand side) does not affect the occurrence of the consequent (right-hand side).
If Lift < 1, means the sale of items in the association rule has a negative relationship. The occurrence of the antecedent decreases the likelihood of the consequent occurring.
If Lift > 1, means the sale of items in the association rule has a positive relationship. The occurrence of the antecedent increases the likelihood of the consequent occurring. The higher the lift, the stronger the association.
For example:
Lift (Perfume -> Soap) = Confidence (Perfume -> Soap) / Support (Soap) = 75/40 = 1.87
This means that perfume and soap have a positive relationship and the presence of perfume boosts the sale of soap.
Data Preparation
The data used for the association rule mining was song lyrics data. This dataset provides a list of lyrics from 1950 to 2019. It contains 28,372 rows and 30 columns. The example of the dataset is shown below.

The data collected is already cleaned. In order to do ARM model, the data had to be transformed into transaction format. The lyrics column which was text data was used to create the transaction data. For the concept of building the transaction file, each lyric should be one transaction and each word (token) in the lyric should be in its own column. The steps to transform text data into transaction data is mentioned below.
- Tokenize Text
Break down the text into smaller units, such as words, phrases, or terms and remove stop words
- Write tokenized text into the file
It concatenates the tokens into a single string

- Read and inspect the transactions

Results
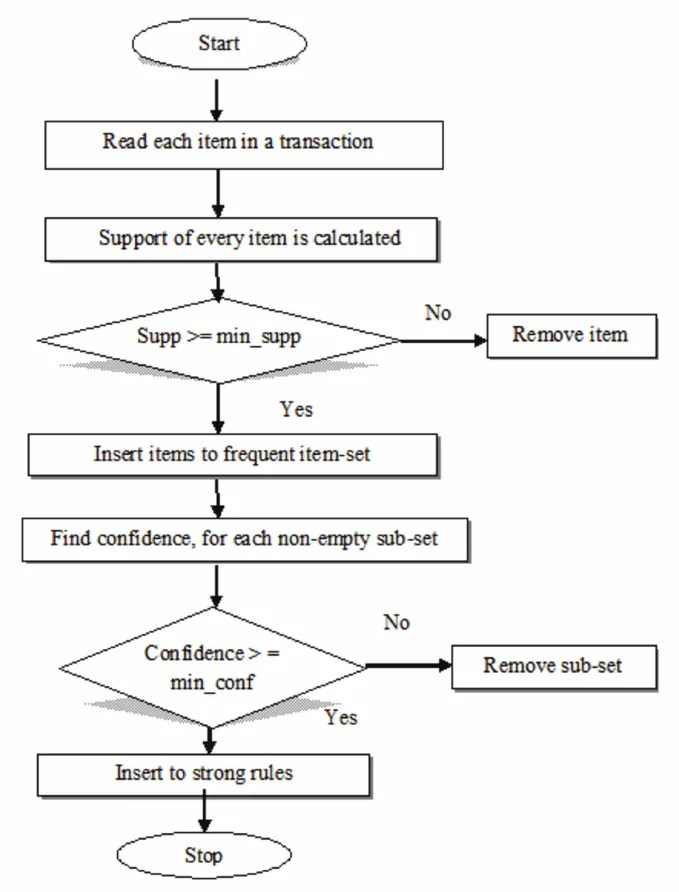
To fit the model, the thresholds were set as follows support = 0.01, confidence = 0.75, min length = 2, and max length = 4. They provide as important role in determining the number of rules generated. However, setting the wrong threshold can lead to the failure of the association rules. After training the apriori model, the results came out as below. Here is the top 15 support values in descending order.

The 15 rules were discovered according to the metrics set by sorting support in descending order. The rules show the most common words in the dataset such as feel, tell, and know. From rule number 1, when there are {feel, tell} in the lyrics, the word {know} will come after these words with the chance of 0.0396 (3.96%) which means that 3.96% of all the songs or instances in the dataset contain the words {feel, tell} along with {know}. Also, many words in the lyrics are related to {know} from these rules. This information can be used to understand the rarity of this combination. In creative endeavors like songwriting, this might suggest an opportunity to use this combination in a unique or creative way to stand out.
Moving on to the association rules sorted by confidence:

From the result above, there is 1 rule that has confidence = 1. Confidence is a valuable measure to understand the likelihood of one event (presence of B) occurring given another event (presence of A). This means that every time when the left-hand side appears, right-hand side always appears as well. So when {feel, forever, time} appear in the lyrics, there is always {know} in the lyrics. Rule 7 can be interpreted as there is {come} 92.86% of the time when the words {get, good, know} appear. This suggests that when a song contains the words {get, good, know}, there is a high probability that it will also include the word {come}.
For the result of the association rules sorted by lift:
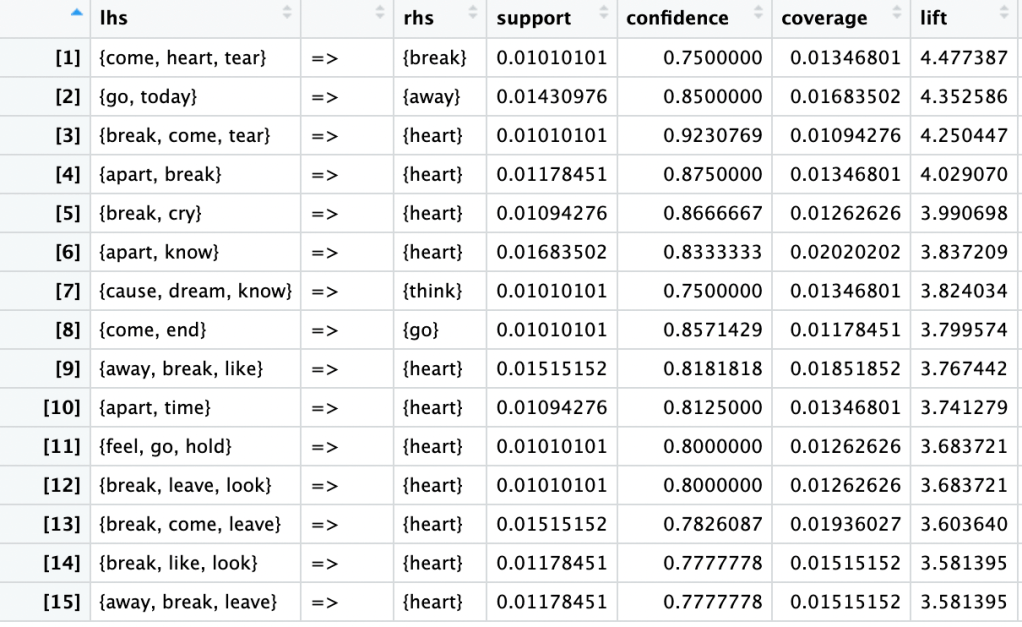
The rules above represent the 15 rules with the highest lift meaning that they are the most positively associated with each other. Rule 1, in the context of song lyrics, when the words {come, heart, tear} are presented in a song, there is a strong tendency for the word {break} to also appear in the lyrics. It might suggest a thematic or emotional association between these words. A lift of 4.477 indicates a strong association. The presence of {come, heart, tear} increases the likelihood of {break} being in the lyrics by approximately 4.477 times compared to what would be expected if the occurrence of {break} was independent of these words.
In order to see the relative frequencies of the most common items in the dataset, a bar chart was created.

The chart above shows the relative item frequencies of the top 10 most common items in the lyrics. This plot helps to understand which items are the most prevalent in the dataset and can provide insights into the frequent terms in song lyrics. The word “know” has the highest frequency appearance in the song lyrics, followed by “like” and come” respectively. This information is valuable for various purposes, including guiding songwriting, or understanding popular trends.
Moving on to the network visualizations, to explain, each node in the network represents an association rule which typically consists of an antecedent (left-hand side) and a consequent (right-hand side). The nodes are positioned based on an algorithm that aims to optimize the layout for clarity and aesthetics, often using force-directed layouts to distribute the nodes in a visually pleasing way. For edges (lines connecting nodes), they represent relationships between the antecedents and consequents of association rules. The presence of an edge signifies that there is a relationship or association between the items in the rule. If the relationship has directions, the line becomes an arrow. Moreover, the thickness or weight of the edges may represent the strength of the association, which is often based on the metric selected. Thicker or darker edges usually indicate stronger associations. The labels on the nodes typically show the items (words, phrases, features) involved in the association rule.



The displayed networks above show graphical visualizations of the top 15 association rules based on their support, confidence, and lift respectively. These are the rules with the highest frequency of occurrence between item in the dataset, as determined by the association rule mining algorithm.
Another association network graph below shows the best 100 association rules with highest lift.

The generated visualization of association rules above emphasizes the measure of confidence and employ shading to represent lift. In this graph, confidence is the measure used to evaluate the rules and determine the edges’ properties. The shading of the visualization will provide insights into the lift associated with each rule, offering a visual representation of the strength and significance of associations between antecedents and consequents based on the specified measures. The main nodes are heart, away, and break. This means that these words are related to songwriting. Also, the nodes are solid red which indicates a positive association. Therefore, it is typically considered desirable in association rule mining as it signifies a meaningful and significant association. It can imply that the presence of the antecedent in a transaction increases the likelihood of finding the consequent in the same transaction more than you would expect by chance. The figure below is the association rule network with confidence and lift shading in htmlwidget. To see the network clearly, click download file here. It is the same network but this one uses the engine called htmlwidget which can be seen more clearly, can select specific nodes, and it is more interactive.

Conclusion
Conducting association rule mining on a dataset of song lyrics can yield valuable insights into the frequent cooccurrences and associations between words, phrases, or themes within the lyrics. In this analysis, association rule mining was applied to a dataset comprising song lyrics, aiming to unravel underlying patterns and connections within the lyrical content. Through this process, several intriguing associations were emerged, shedding light on prevalent themes and stylistic elements in the world of songwriting.
The association rules highlighted significant connections between terms such as “feel”, “like”, “break”, and “heart”. The results found show how underscoring the ubiquitous theme of love and its complexities from the rules. This can be concluded that heartfelt expressions of love, like, and heartache might be central elements in song composition. Furthermore, there are a few words that are about motivated living that normally appear in the songs like “go”, “life”, and “think”, suggesting that imply action, forward movement, contemplation, or cognitive activity.
To summarize, these association rules provide compelling insights into the thematic and emotional landscape of song lyrics. They can give more valuable guidance to songwriters, artists, and producers, aiding in the creation of music that resonates with a broader audience. Moreover, the analysis demonstrates the potential of association rule mining in unveiling recurrent patterns and inspiring creativity within the realm of songwriting offering a deeper understanding of the artistic and emotional dimensions present in music.
